AI/ML producers of chips also suggest technology named model zoo. Usually a zoo is a set of AI/ML models adapted in order to comply with the concrete AI architecture having its own distinctive characteristics. To define the size of a model zoo, it is necessary to base on the size of the company’s software resource. The thing is that models have to be transformed and retrained.
AI model zoo produced by MemryX is unusual since the MX3 is able to conduct trained AI models after only a 1-click compilation. The result has been achieved by the company through validation of hundreds of trained AI/ML models that were extracted from the storages on the web and from partners and customers. According to the company, the 1-click compilation process gives utilization rate of 50-80%.
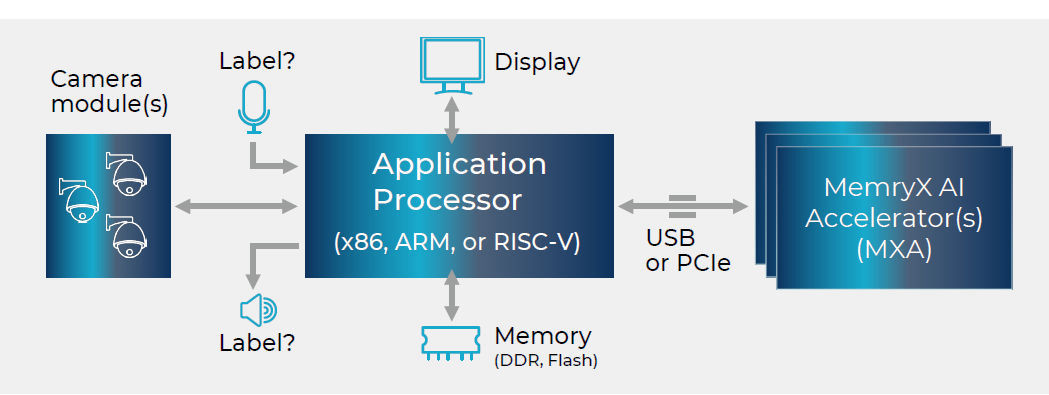
The MX3 does not relate to stand-alone AI/ML gadgets. It has to work in pair with a host CPU, connected by either a PCIe or USB interface. Thanks to this technology it becomes easy to implement the gadget into diverse hardware designs, including the old ones.
Nowadays everyone has an extra port around. The MX3 accelerators do not demand outer memory, so implementation of AI/ML model processing capability to a gadget’s hardware design becomes not harder than supply a port connection between the CPU and the MX3 accelerator.
MemryX MX3 accelerator chip increases AI/ML processing efficiency by about 5 TFLOPS (trillion floating-point operations per second). For the purpose of activations and a layer-by-layer choice of 4-, 8-, the gadget utilizes bfloat16 numbers internally and for weights it utilizes 16-bit integers. MX3 gadgets are aimed to be daisy chained, that is why their processing ability increases as the number of implemented chips grows thanks to “at-memory” and dataflow architecture.
Thereby, a 2-device array of MX3 accelerators gives 10 TFLOPS and a 4-device array gives 20 TFLOPS. An MX3 gadget taken separately utilizes around 1 watt of energy and is able to work with a high number of AI/ML models at the same time in case they suit the MX’s on-chip weight memory. Besides, you can change the models and the procedure takes you no more than 10 milliseconds.
With the help of a 1-click compilation technology the MX3 development flow can work with many wide-spread AI/ML development frameworks such as PyTorch, ONNX, Tensorflow, Tensorflow-Lite and Keras. Accelerators with a dataflow orientation similar to MX3 are able to cope with microprocessors or microcontrollers based on any architecture (Arm, x86, RISC-V, etc.), as well as any operating system. This way, the advantages of MX3 accelerator makes it easy in use for many design teams.
